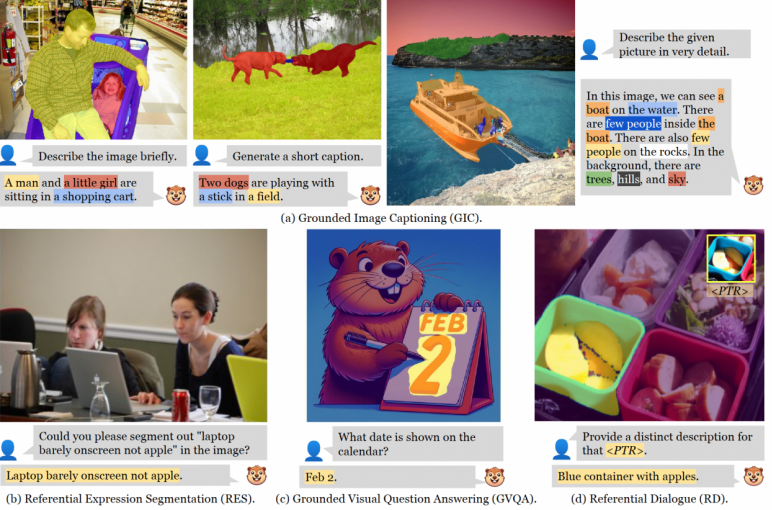
 图 | GROUNDHOG 支持的任务示例(来源:arXiv)针对这些问题,美国密歇根大学博士生张亦弛和所在团队提出了 GROUNDHOG,这是一个可以支持大型语言模型与视觉实体进行像素级语义对齐的 Grounded MLLM 模型。
图 | GROUNDHOG 支持的任务示例(来源:arXiv)针对这些问题,美国密歇根大学博士生张亦弛和所在团队提出了 GROUNDHOG,这是一个可以支持大型语言模型与视觉实体进行像素级语义对齐的 Grounded MLLM 模型。 图 | 张亦弛(来源:张亦弛)对于已有的 MLLM 模型来说,其采用输入 patch-level 视觉特征后直接输出定位坐标的黑盒架构。而 GROUNDHOG 的关键思想是将 Language Grounding(语言接地)解藕成两个阶段:定位和识别。在定位阶段:首先,由一个可以提出各种不同实体区域分割的专家模型,提供图像中所有实体的分割。然后,通过一个掩码特征提取器,提取每个实体的视觉特征,以此作为多模态语言模型的输入。在识别阶段:当大语言模型解码出可进行视觉锚定的短语时,就会从输入的所有实体中,选择相应的实体分割进行融合,借此得到文本对应的视觉分割区域。这种分离的设计不仅允许独立优化实体分割模型和多模态语言模型,还提高了错误分析的可解释性,并允许 MLLM 与多种视觉专家模型灵活结合,从而提高整体性能。
图 | 张亦弛(来源:张亦弛)对于已有的 MLLM 模型来说,其采用输入 patch-level 视觉特征后直接输出定位坐标的黑盒架构。而 GROUNDHOG 的关键思想是将 Language Grounding(语言接地)解藕成两个阶段:定位和识别。在定位阶段:首先,由一个可以提出各种不同实体区域分割的专家模型,提供图像中所有实体的分割。然后,通过一个掩码特征提取器,提取每个实体的视觉特征,以此作为多模态语言模型的输入。在识别阶段:当大语言模型解码出可进行视觉锚定的短语时,就会从输入的所有实体中,选择相应的实体分割进行融合,借此得到文本对应的视觉分割区域。这种分离的设计不仅允许独立优化实体分割模型和多模态语言模型,还提高了错误分析的可解释性,并允许 MLLM 与多种视觉专家模型灵活结合,从而提高整体性能。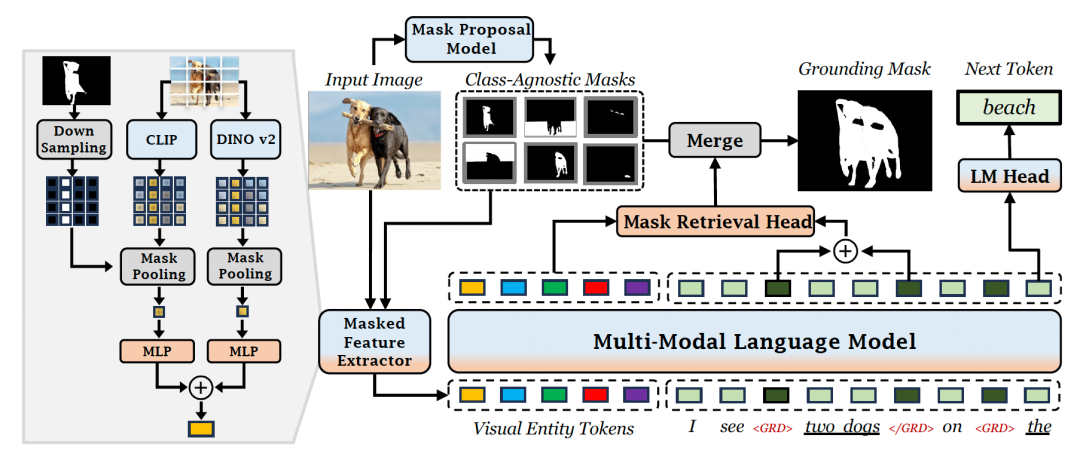 图 | GROUNDHOG 架构(来源:arXiv)此外,GROUNDHOG 的这种设计模式可以自然拓展到区域级的图像理解任务,能够灵活地接受任何图像中的位置和区域指代方式来作为输入。另据悉,不同于 GPT4ROI、Ferret 等现有模型需要引入额外的 spatial prompt encoder,GROUNDHOG 可以直接和 SAM(Segment Anything)等预训练专家模型结合,从而处理位置的指代输入,进而极大拓展应用场景。
图 | GROUNDHOG 架构(来源:arXiv)此外,GROUNDHOG 的这种设计模式可以自然拓展到区域级的图像理解任务,能够灵活地接受任何图像中的位置和区域指代方式来作为输入。另据悉,不同于 GPT4ROI、Ferret 等现有模型需要引入额外的 spatial prompt encoder,GROUNDHOG 可以直接和 SAM(Segment Anything)等预训练专家模型结合,从而处理位置的指代输入,进而极大拓展应用场景。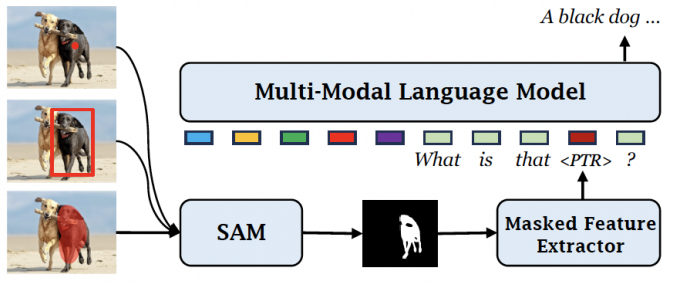 图 | 与 SAM 无缝衔接处理各种形式的位置提示输入(来源:arXiv)据了解,为了训练 GROUNDHOG,课题组整合了 27 个现有数据集的 2.5M 文本-图像对,并进行了衍生和增强。通过此,他们组成一个名为 M3G2 的新数据集,以便用于学习多模态多粒度的视觉文本对齐能力。M3G2 包括图文锚定描述、指代物体分割、图文锚定问答、视觉指代对话 4 大类任务,涵盖 36 种子任务,具备丰富的视觉文本对齐标注能力。
图 | 与 SAM 无缝衔接处理各种形式的位置提示输入(来源:arXiv)据了解,为了训练 GROUNDHOG,课题组整合了 27 个现有数据集的 2.5M 文本-图像对,并进行了衍生和增强。通过此,他们组成一个名为 M3G2 的新数据集,以便用于学习多模态多粒度的视觉文本对齐能力。M3G2 包括图文锚定描述、指代物体分割、图文锚定问答、视觉指代对话 4 大类任务,涵盖 36 种子任务,具备丰富的视觉文本对齐标注能力。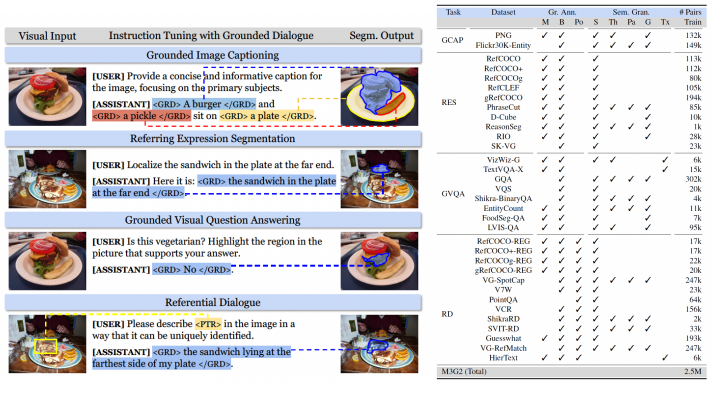 图 | M3G2 数据集的 4 种任务示例及数据统计(来源:arXiv)通过相关实验,该团队证明 GROUNDHOG 在各种视觉文本对齐任务上,都能达到很好的性能,且无需针对特定任务进行微调。此外,GROUNDHOG 能显著减少视觉幻觉现象的出现,并在失败案例中提供了易于理解的诊断信息,为需要精确视觉理解和自然语言处理的领域的发展奠定了一定基础。
图 | M3G2 数据集的 4 种任务示例及数据统计(来源:arXiv)通过相关实验,该团队证明 GROUNDHOG 在各种视觉文本对齐任务上,都能达到很好的性能,且无需针对特定任务进行微调。此外,GROUNDHOG 能显著减少视觉幻觉现象的出现,并在失败案例中提供了易于理解的诊断信息,为需要精确视觉理解和自然语言处理的领域的发展奠定了一定基础。 (来源:arXiv)GROUNDHOG 模型的一个典型应用场景,便是在可穿戴设备中,推动多模态 AI 助手的发展。试想这样一个情境:当顾客佩戴智能眼镜在商场购物时,对着某个品牌的商品询问 AI 助手:“这个商品好吗,有更好评价的吗?”AI 助手不仅能精确地识别顾客所指商品并能提供相关评价信息,还能智能推荐货架上其他评价更高的商品。以及能在眼镜屏幕上通过增强现实技术,高亮地显示这些商品,便于顾客查找和比较。在顾客与多模态 AI 助手的互动中,这种结合视线追踪理解用户意图的能力,加上视觉锚定增强输出文本的效果,不仅可以提升交互的自然性,也能极大增强用户体验。“也就是说,GROUNDHOG 模型正是在这两个关键能力上表现出色,从而能为推动下一代多模态 AI 助手的革新奠定基础。”研究人员表示。GROUNDHOG 的另一个应用前景,在于能够驱动具身 AI 智能体。比如,可以设计一个网络浏览机器人,它通过接收网页截图和用户意图描述作为输入,并输出相应的鼠标操作或键盘操作。在这个场景中,点击网页元素——可被视作结合输出文本(动作)和网页交互元素位置的交互行为。比如,智能体输出的动作为“点击‘提交’按钮”,然后识别并定位到截图中的“提交”按钮,并执行实际的点击操作。研究人员表示:“GROUNDHOG 所提供的 Grounding 能力在这种视觉语言理解与动作执行相结合的应用场景中至关重要,进一步拓宽了多模态语言模型在用于 AI 智能体决策中的应用范围。”事实上,该团队最开始的研究动机是因为观察到了多模态大语言模型中普遍存在的视觉幻觉现象,希望探索缓解这个问题的解决方案。经过深入思考之后,他们认为幻觉现象出现的根源还是在于模型视觉文本对齐能力的缺失。而现有模型由于架构上的限制,很难支持精细的像素级文本对齐。由此便想到:为何不打造一款新模型去解决这个问题呢?于是研究重心就从缓解视觉幻觉转移到开发一款具备较强像素级视觉文本对齐能力的模型。幸运的是,当他们的架构能够运营之后,该团队在实验中发现确实极大缓解了大模型的视觉幻觉问题,因此也算完成了他们的初衷。与此同时,在确定研究问题之后,很快他们就发现了现有模型存在可解释性较差的问题,于是便确定了“先定位后识别”的主要框架。随后,课题组开始寻找具体的实体分割模型。期间遇到了一些困难:其希望这个实体分割模型可以提供语义丰富、粒度多样、高质量的实体分割图片标签。然而,在已有的预训练分割模型中,要么只能给出有限的实体类别,要么无法很好地支持他们想要的多粒度分割。总之,并没有可以满足研究人员全部需求的模型。因此,他们通过整合 COCO、LVIS、PACO、Entity-V2、TextOCR 等现有的分割数据集,基于一个修改后的 Mask2Former 架构自行训练了一个支持多样、全面分割的模型 Mask2Former+,以此作为他们的实体分割模型。而在当时,另一个重要问题就是构建训练模型的数据集。构建这种具备较为复杂的细粒度图像文本对齐标注的数据集一般有两种方式:要么通过重新整合现有数据集,要么通过现有的大模型对图像进行标注加工。出于对任务丰富性和数据质量的考虑,他们选择了前者,并尽可能地收集了学术界已有的能够纳入本次任务框架的数据集。随后,该团队通过 ChatGPT 生成了对话模板,将所有数据整合为了人机对话的形式。最后,他们选择在视觉文本对齐任务中一些比较有代表性的 benchmark,对本次模型加以量化评测与分析。日前,相关论文以《GROUNDHOG:将大型语言模型建立在整体分割的基础上》(GROUNDHOG:Grounding Large Language Models to Holistic Segmentation)为题发在 arXiv[1]。
(来源:arXiv)GROUNDHOG 模型的一个典型应用场景,便是在可穿戴设备中,推动多模态 AI 助手的发展。试想这样一个情境:当顾客佩戴智能眼镜在商场购物时,对着某个品牌的商品询问 AI 助手:“这个商品好吗,有更好评价的吗?”AI 助手不仅能精确地识别顾客所指商品并能提供相关评价信息,还能智能推荐货架上其他评价更高的商品。以及能在眼镜屏幕上通过增强现实技术,高亮地显示这些商品,便于顾客查找和比较。在顾客与多模态 AI 助手的互动中,这种结合视线追踪理解用户意图的能力,加上视觉锚定增强输出文本的效果,不仅可以提升交互的自然性,也能极大增强用户体验。“也就是说,GROUNDHOG 模型正是在这两个关键能力上表现出色,从而能为推动下一代多模态 AI 助手的革新奠定基础。”研究人员表示。GROUNDHOG 的另一个应用前景,在于能够驱动具身 AI 智能体。比如,可以设计一个网络浏览机器人,它通过接收网页截图和用户意图描述作为输入,并输出相应的鼠标操作或键盘操作。在这个场景中,点击网页元素——可被视作结合输出文本(动作)和网页交互元素位置的交互行为。比如,智能体输出的动作为“点击‘提交’按钮”,然后识别并定位到截图中的“提交”按钮,并执行实际的点击操作。研究人员表示:“GROUNDHOG 所提供的 Grounding 能力在这种视觉语言理解与动作执行相结合的应用场景中至关重要,进一步拓宽了多模态语言模型在用于 AI 智能体决策中的应用范围。”事实上,该团队最开始的研究动机是因为观察到了多模态大语言模型中普遍存在的视觉幻觉现象,希望探索缓解这个问题的解决方案。经过深入思考之后,他们认为幻觉现象出现的根源还是在于模型视觉文本对齐能力的缺失。而现有模型由于架构上的限制,很难支持精细的像素级文本对齐。由此便想到:为何不打造一款新模型去解决这个问题呢?于是研究重心就从缓解视觉幻觉转移到开发一款具备较强像素级视觉文本对齐能力的模型。幸运的是,当他们的架构能够运营之后,该团队在实验中发现确实极大缓解了大模型的视觉幻觉问题,因此也算完成了他们的初衷。与此同时,在确定研究问题之后,很快他们就发现了现有模型存在可解释性较差的问题,于是便确定了“先定位后识别”的主要框架。随后,课题组开始寻找具体的实体分割模型。期间遇到了一些困难:其希望这个实体分割模型可以提供语义丰富、粒度多样、高质量的实体分割图片标签。然而,在已有的预训练分割模型中,要么只能给出有限的实体类别,要么无法很好地支持他们想要的多粒度分割。总之,并没有可以满足研究人员全部需求的模型。因此,他们通过整合 COCO、LVIS、PACO、Entity-V2、TextOCR 等现有的分割数据集,基于一个修改后的 Mask2Former 架构自行训练了一个支持多样、全面分割的模型 Mask2Former+,以此作为他们的实体分割模型。而在当时,另一个重要问题就是构建训练模型的数据集。构建这种具备较为复杂的细粒度图像文本对齐标注的数据集一般有两种方式:要么通过重新整合现有数据集,要么通过现有的大模型对图像进行标注加工。出于对任务丰富性和数据质量的考虑,他们选择了前者,并尽可能地收集了学术界已有的能够纳入本次任务框架的数据集。随后,该团队通过 ChatGPT 生成了对话模板,将所有数据整合为了人机对话的形式。最后,他们选择在视觉文本对齐任务中一些比较有代表性的 benchmark,对本次模型加以量化评测与分析。日前,相关论文以《GROUNDHOG:将大型语言模型建立在整体分割的基础上》(GROUNDHOG:Grounding Large Language Models to Holistic Segmentation)为题发在 arXiv[1]。 图 | 相关论文(来源:arXiv)关于上述数据集和本次模型的详细介绍,可以参考本次论文的附录。之后,他们也会将这部分数据处理和模型训练的代码一并公开。后续,他们希望能将 GROUDHOG 拓展到第一视角视频,打造一个能够处理视频输入的 Grounded MLLM 个人助手。参考资料:1.https://arxiv.org/pdf/2402.16846
图 | 相关论文(来源:arXiv)关于上述数据集和本次模型的详细介绍,可以参考本次论文的附录。之后,他们也会将这部分数据处理和模型训练的代码一并公开。后续,他们希望能将 GROUDHOG 拓展到第一视角视频,打造一个能够处理视频输入的 Grounded MLLM 个人助手。参考资料:1.https://arxiv.org/pdf/2402.16846排版:初嘉实
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
