如果你关注数码科技,那么你一定对“性能过剩论”不陌生。对于普通用户来说,如今的芯片性能足以应对大多数的日常场景。 然而,人工智能应用领域的热潮似乎又重新点燃了许多人对于算力的需求。与此同时,在图形处理与渲染、高性能计算等领域,人们对提升处理器性能的追求从未停歇。 不过,在摩尔定律与登纳德缩放定律都面临危机的今天,除了依赖制程的发展和核心数的增加,我们还能找到其他可行的路径来提升计算机性能吗? 近期,由美国加州大学河滨分校的副教授曾宏伟(Hung-Wei Tseng)领导的研究团队,提出了一种以新的软件框架提高现有计算机处理速度的方法,为我们提供了一种新的性能提升思路。  图丨曾宏伟(来源:加州大学河滨分校) 为了处理不同类型的数据,现代计算机大都集成了多种处理器,并引入异构计算模型以提升性能。
图丨曾宏伟(来源:加州大学河滨分校) 为了处理不同类型的数据,现代计算机大都集成了多种处理器,并引入异构计算模型以提升性能。
然而,由于传统的编程框架,包括领域特定语言(domain-specific languages),只能将代码区域(code region)分配给一种处理器,使得其他计算资源闲置而无法用于当前函数的运算,因此现有编程模型并不能充分发挥异构模型的潜力。 而这项名为“同步异构多线程”(simultaneous and heterogenous multithreading,SHMT)的编程和执行模型,旨在克服现有编程模型未能充分利用异构计算系统潜力的限制。 与传统模型不同,SHMT 可以充分利用异构的并行类型。通过结合多种处理单元(如 CPU、GPU、TPU 等)的优势,这种模型能有效提升计算效率和能效。 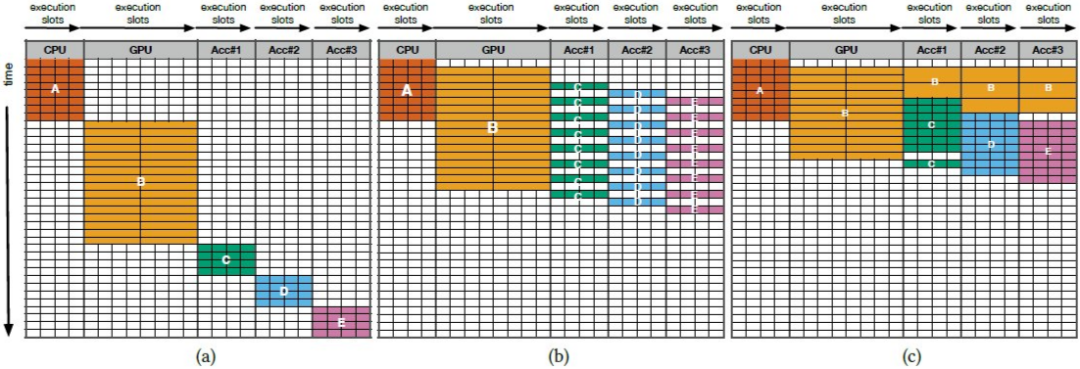 图丨 SHMT 的执行模型(c)相比于传统异构计算机(a)与使用了软件流水技术的传统异构计算机(b)的优势(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture) 此前的研究已经证明,使用了不同处理模型与设计理念的协处理器和硬件加速器,都能以出色的性能执行相同的函数,这为 SHMT 的实现提供了可能。不过,要将同一函数的计算分解到不同类型的计算资源中,系统面临以下三个挑战: 第一,SHMT 需要某种机制来描述和划分在不同的计算分区上的等效操作和数据; 第二,SHMT 必须能够高效地协调异构硬件上的执行; 第三,由于不同的硬件单元会提供不同质量水平的结果,SHMT 必须在不产生大量额外开销的情况下确保结果。 为了解决这些困难,研究人员开发了一个由三个主要部分组成的系统架构: 首先,SHMT 引入了一种虚拟硬件的概念,允许开发者将计算任务借助一系列虚拟操作(Virtual Operations,VOPs)的形式从 CPU“卸载”。
图丨 SHMT 的执行模型(c)相比于传统异构计算机(a)与使用了软件流水技术的传统异构计算机(b)的优势(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture) 此前的研究已经证明,使用了不同处理模型与设计理念的协处理器和硬件加速器,都能以出色的性能执行相同的函数,这为 SHMT 的实现提供了可能。不过,要将同一函数的计算分解到不同类型的计算资源中,系统面临以下三个挑战: 第一,SHMT 需要某种机制来描述和划分在不同的计算分区上的等效操作和数据; 第二,SHMT 必须能够高效地协调异构硬件上的执行; 第三,由于不同的硬件单元会提供不同质量水平的结果,SHMT 必须在不产生大量额外开销的情况下确保结果。 为了解决这些困难,研究人员开发了一个由三个主要部分组成的系统架构: 首先,SHMT 引入了一种虚拟硬件的概念,允许开发者将计算任务借助一系列虚拟操作(Virtual Operations,VOPs)的形式从 CPU“卸载”。
VOPs 定义了 SHMT 底层硬件可支持的可用操作,进而使整个 SHMT 子系统抽象为一个单一且强大的加速器。
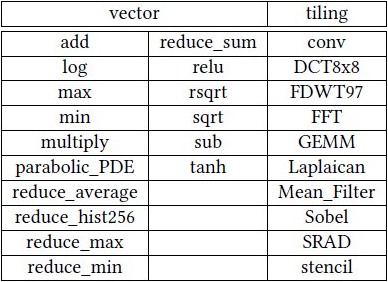 图丨矢量或矩阵平铺处理模型类型的 VOP 列表(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture) 其次,SHMT 有一套至关重要的运行时系统。它不仅作为虚拟硬件的“驱动程序”,在程序执行期间动态解析 VOPs,还负责评估硬件资源的能力,并据此做出智能的调度决策。它将 VOPs 进一步分解为高级操作(High-Level Operations,HLOPs),这些 HLOP 作为 SHMT 中的基本调度单位,每个 HLOP 负责执行 VOP 运算的特定部分,且均具有硬件无关性,确保了运行时系统能够根据实际情况灵活调整任务分配。 更进一步地,SHMT 采用了一种质量感知的工作窃取(Quality-Aware Work-Stealing,QAWS)调度策略,以优化资源利用率和提升系统性能。这种策略通过动态调整工作负载分配来平衡各种硬件资源的使用,减少空闲时间,避免性能瓶颈,同时保证了任务执行的质量。
图丨矢量或矩阵平铺处理模型类型的 VOP 列表(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture) 其次,SHMT 有一套至关重要的运行时系统。它不仅作为虚拟硬件的“驱动程序”,在程序执行期间动态解析 VOPs,还负责评估硬件资源的能力,并据此做出智能的调度决策。它将 VOPs 进一步分解为高级操作(High-Level Operations,HLOPs),这些 HLOP 作为 SHMT 中的基本调度单位,每个 HLOP 负责执行 VOP 运算的特定部分,且均具有硬件无关性,确保了运行时系统能够根据实际情况灵活调整任务分配。 更进一步地,SHMT 采用了一种质量感知的工作窃取(Quality-Aware Work-Stealing,QAWS)调度策略,以优化资源利用率和提升系统性能。这种策略通过动态调整工作负载分配来平衡各种硬件资源的使用,减少空闲时间,避免性能瓶颈,同时保证了任务执行的质量。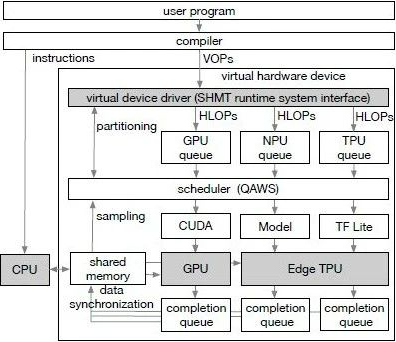
图丨SHMT 概览(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture)
为了检验这一模型,该课题组使用 NVIDIA Jetson Nano 模块定制了一个嵌入式系统平台,以模拟移动设备、数据中心服务器等常见使用场景进行验证。该系统原型由下图所示部分构成: 图丨 SHMT 原型平台构成示意图(来源:DeepTech)在基准应用程序上的检测结果显示,相较于基准方法,采用性能最佳策略的 QAWS 的 SHMT 速度提高了 1.95 倍。 实验表明,所有 QAWS 策略均能有效地提高结果质量,MAPE(平均绝对百分比误差)平均值低于 2%,接近于手动优化的 Oracle 场景。且无论采样率如何变化,QAWS-TS 策略的性能都名列前茅。
图丨 SHMT 原型平台构成示意图(来源:DeepTech)在基准应用程序上的检测结果显示,相较于基准方法,采用性能最佳策略的 QAWS 的 SHMT 速度提高了 1.95 倍。 实验表明,所有 QAWS 策略均能有效地提高结果质量,MAPE(平均绝对百分比误差)平均值低于 2%,接近于手动优化的 Oracle 场景。且无论采样率如何变化,QAWS-TS 策略的性能都名列前茅。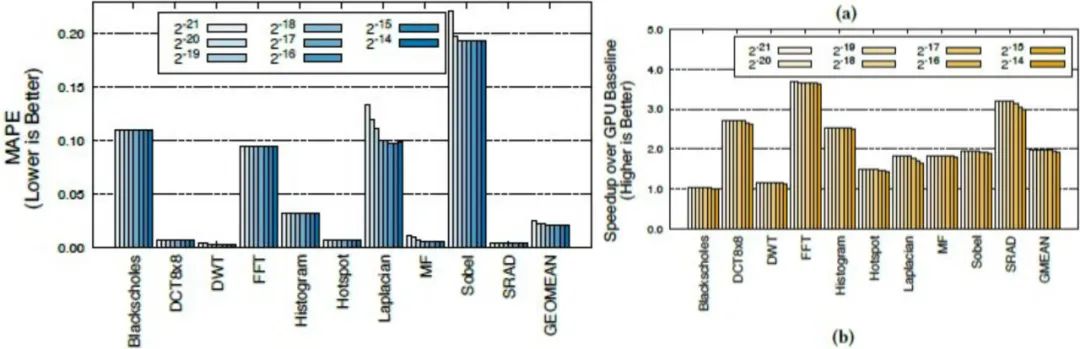 图丨(a)质量与 QAWS 采样率的关系,(b)速度提升与 QAWS 采样率的关系(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture) 更为重要的是,由于 SHMT 减少了执行时间,并将计算任务转移到耗电更低的 Edge TPU 上,因此它在节约能耗方面展现出了巨大潜力。实验结果显示,与基线 GPU 相比,SHMT 在 QAWS-TS 策略下平均减少了 51% 的能耗和 78% 的能量延迟积。同时,得益于 Edge TPU 专用逻辑提供的加速功能,以及 SHMT 并行编程模型使用的低数据交换算法,这一模型也不会导致显著的内存和通信开销。
图丨(a)质量与 QAWS 采样率的关系,(b)速度提升与 QAWS 采样率的关系(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture) 更为重要的是,由于 SHMT 减少了执行时间,并将计算任务转移到耗电更低的 Edge TPU 上,因此它在节约能耗方面展现出了巨大潜力。实验结果显示,与基线 GPU 相比,SHMT 在 QAWS-TS 策略下平均减少了 51% 的能耗和 78% 的能量延迟积。同时,得益于 Edge TPU 专用逻辑提供的加速功能,以及 SHMT 并行编程模型使用的低数据交换算法,这一模型也不会导致显著的内存和通信开销。 图 | 相关论文(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture)近日,相关论文以《同步异构多线程》(Simultaneous and Heterogenous Multithreading)为题,在加拿大多伦多举行的第 56 届 IEEE/ACM 国际微架构研讨会上发表[1]。加州大学河滨分校的博士研究生徐冠杰(Kuan-Chieh Hsu)为第一作者,曾宏伟副教授担任通讯作者。曾宏伟对媒体表示,“你不必增加新的处理器,因为现有的就足够了。”因此,仅需使用现有的处理组件,就相当于降低了计算机硬件成本,同时减少了服务器等设备运行时的能源消耗,也减少了碳排放与水消耗。 但这一模型也面临一些挑战与局限性。例如,如何有效管理和调度多种类型的计算资源以实现最优能效、如何降低编程模型的复杂性、如何降低通信开销以及如何扩展应用平台与场景等问题,而这些也正是曾宏伟团队未来的研究方向。
图 | 相关论文(来源:the 56th Annual IEEE/ACM International Symposium on Microarchitecture)近日,相关论文以《同步异构多线程》(Simultaneous and Heterogenous Multithreading)为题,在加拿大多伦多举行的第 56 届 IEEE/ACM 国际微架构研讨会上发表[1]。加州大学河滨分校的博士研究生徐冠杰(Kuan-Chieh Hsu)为第一作者,曾宏伟副教授担任通讯作者。曾宏伟对媒体表示,“你不必增加新的处理器,因为现有的就足够了。”因此,仅需使用现有的处理组件,就相当于降低了计算机硬件成本,同时减少了服务器等设备运行时的能源消耗,也减少了碳排放与水消耗。 但这一模型也面临一些挑战与局限性。例如,如何有效管理和调度多种类型的计算资源以实现最优能效、如何降低编程模型的复杂性、如何降低通信开销以及如何扩展应用平台与场景等问题,而这些也正是曾宏伟团队未来的研究方向。
参考文献:
1.Kuan-Chieh Hsu and Hung-Wei Tseng. 2023. Simultaneous and Heterogenous Multithreading. In Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO '23). Association for Computing Machinery, New York, NY, USA, 137–152. https://doi.org/10.1145/3613424.3614285
2.https://news.ucr.edu/articles/2024/02/21/method-identified-double-computer-processing-speeds
支持:Ren
排版:刘雅坤
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
