曾忠燊,是一名潮汕人。其本科和硕士分别毕业于美国伊利诺伊大学和美国佐治亚理工学院。在本科毕业和硕士毕业之后,他曾先后在 IBM-Research 和深圳 IDEA 研究院工作过一段时间。
在 ChatGPT 面世以后,他意识到针对大模型的研究范式存在一定的不足,于是决定来到香港中文大学读博。

图 | 曾忠燊(来源:曾忠燊)
前不久,曾忠燊和所在团队提出一个全新评测范式。基于这一评测范式,他们又针对现有数据集,提出了一种改造方法。
实验证明,这种方法能有效区分不同模型的能力差异。同时,他们还揭示了这种全新评测范式对于当前数据污染的鲁棒性。
此前,由于训练数据的不透明,人们无法得知大模型在一些榜单上的成绩提升,是否是数据污染和题目泄露所带来的。
而本次提出的全新评测范式,对于“背题”式的成绩提高有着极强的抵御能力。凭借这种抵御能力,就能对绝大部分的数据集进行“旧改”。
同时,这种全新的评测方式不仅可以揭示大模型的能力差异,也能给下游应用带来一定启示。
日前,相关论文以《大型语言模型评价中的元推理革命》(MR-GSM8K: A Meta-Reasoning Revolution in Large Language Model Evaluation)为题发在 arXiv,曾忠燊是第一作者,香港中文大学教授贾佳亚担任通讯作者 [1]。

图 | 相关论文(来源:arXiv)

大模型也在依靠“题海战术”?
“背题”“题海战术”,是许多人在读书时代都曾使用过的学习方式。然而,你可知道大模型其实也在使用这两种学习方式?此外,当前大模型的能力边界到底在哪里?
从推理和认知这两个能力维度出发,当一篇论文称大模型在一个评测指标上取得超出人类水平的结果时,我们是否应该感到恐慌?
还是仔细审视在制定指标时是否忽略了什么因素,以至于大模型的认知能力被夸大了?
事实上,对于指标的设计意义思考不足,起码会带来以下几个潜在危害:
其一,评测结果能否真实反映大模型的能力?如果对此认识不足,往往会过分夸大模型的效果。
其二,会让人以为指标的提升,等价于大模型能力的提升、以及等价于真实场景的效果和实用性提升,导致盲目追逐和攀比榜单效果,陷入恶性循环。
其三,过分关注和比较在细分场景上的表现,忽视了大模型整体认知能力的提升。
当前,面向大模型推理能力和认知能力的评测集,主要依赖一些标准化考试的试题、或一些精心设计的规则类游戏。
这些评测集的设计初衷,很大程度上是设计者认为求解这类推理类任务所需要的模式识别、记忆召回、分析假设、归纳演绎等能力,是一种处理所有任务都需要的“元”能力,并认为这类能力对于大模型在现实场景中的泛化和鲁棒是至关重要的。
但是,具体到设计这些任务的评测方式时,这些评测集往往仅仅依赖于对最终计算结果的简单匹配,而忽略了对于计算过程的认知检测。
由此可见,这种目标和实现方式的背离,在很大程度上加剧了大模型评测领域的种种乱象。
举个例子,在图像识别里有一个著名的“走捷径”案例,它指的是在对狼和雪狼进行分类时,大模型学习到的规律是识别背景是否存在积雪,而不是识别两种动物的生理特征区别。
而在认知推理类的数据集上也存在着类似现象。面对一道数学题,假如要求大模型给出分步推理的“思维链”时,大模型往往会混淆不同单位的量,比如将时速和公里数相乘相加,这说明对于不同概念背后的物理意义,大模型存在认识不足的问题。
那么,如何更好地检测大模型对于概念的认知水平、以及检测它的应用泛化能力?
以下图为例,对于一个复杂的推理问题来说,假如从起点到终点有多种解答方式,而其中每一步的推理都能被看成是一个节点,节点和节点之间组成了路径。
而在当前的大模型训练范式中,往往只让大模型看到少数几条正确的解题路径(青色或蓝色),而忽视了错误的路径(橙色)。
同样地,在评测大模型的表现时,人们只关注最终的推理路径终点是否和标准答案一致,而忽视了推理过程中可能存在的错误推理节点或错误路径。
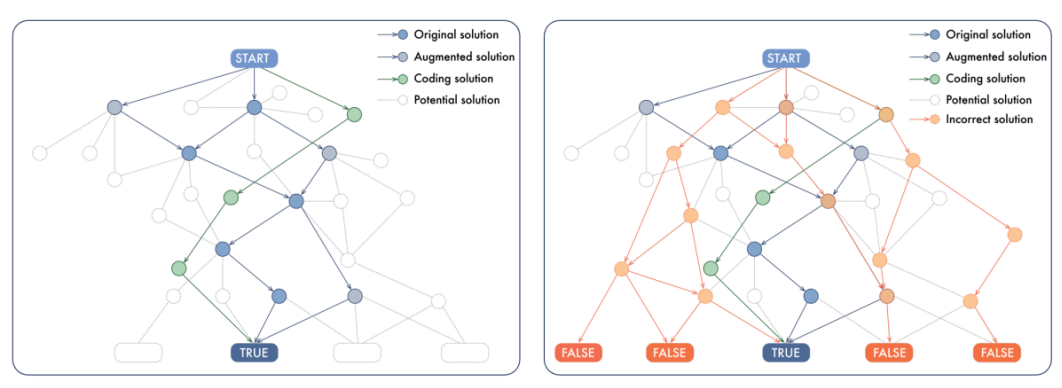
(来源:arXiv)
举例来说:
在教育领域,如果 GPT4 在小学级别的数学题目上的评测准确率只有四成,那么我们难免会对 GPT4 的实用性产生怀疑。
在咨询领域,大模型的应用场景高度依赖于对不同方案的推演、整体步骤的拆分、解析等能力。
而当今大模型在这些方面的能力缺失,难免让人对其下游应用的可靠性打上了问号。

让大模型“从学生变为老师”
基于此,曾忠燊和所在团队开展了本次研究。事实上,本次研究的灵感来源于一次比赛,此前曾忠燊参加了“粤港澳大湾区(黄埔)国际算法算例大赛”的分赛道“大语言模型综合能力强化”。
当时,他调研了一些关于大模型推理方向能力增强的论文,这些论文主要分为以下方向:第一个方向是同源数据增广,第二个方向是使用反馈模型针对数据筛选、或针对大模型进行强化学习训练。
在他尝试使用时,却发现这两个方法均存在很大问题:
第一,当使用 ChatGPT 进行数据增广时,ChatGPT 并不能真正地理解人们希望其生成的一些概念,在应用这些概念造题和解题时常常会出现各种错误,因此往往需要非常精细的程序设计和引导来提升准确率。
第二,仔细研究反馈模型的作用后,曾忠燊认为要求一个反馈模型对推理数据进行筛选时,实质上等价于要求其进行“元推理”。
这一难度甚至高于直接解题,原因在于为了提升解题效果引入更难的评判解题任务,似乎会把一个问题转为另一个更难的问题。
意识到这一问题之后,他和所在团队研发了元推理范式,并将其用于一些常见数据集之上。
结果发现无论是开源大模型还是闭源大模型,它们的表现都开始出现急剧下降,尤其是开源的垂类推理大模型甚至降到了不足百分之一的准确率。
因此,他和同事呼吁将大模型认知推理的检测重点,从最终的计算结果匹配,转移到对于计算过程的检测。
具体做法是:先从解题空间里采样一些给定的推理路径,然后让大模型进行评判。评判的内容包括:推理路径是否正确?错误节点和错误步骤在哪里?错误原因是什么?
这种评测范式的转变,意味着对于整个解题空间,大模型都必须具备全局和宏观的理解,做到知其然也要知其所以然。
详细来说,大模型需要做到如下几方面:
其一,需要知道推理的最终结果和节点是什么;
其二,需要对每一步推理节点的条件和前提进行审视性评判,并对节点和节点间的逻辑连接进行思考,以便判断当前步骤是否出错;
其三,需要能够代入不同假设,或反事实地(counterfactually)针对未来的推理路径进行预演和分析,从而判断这一答案是否在正确的推理路径上。
这些需求将迫使大模型从一个答题者的角度,上升到一个教师的高度进行全局审视和全局推理。对于这种“对推理过程的推理”,该团队将其称之为“元推理”评测范式。
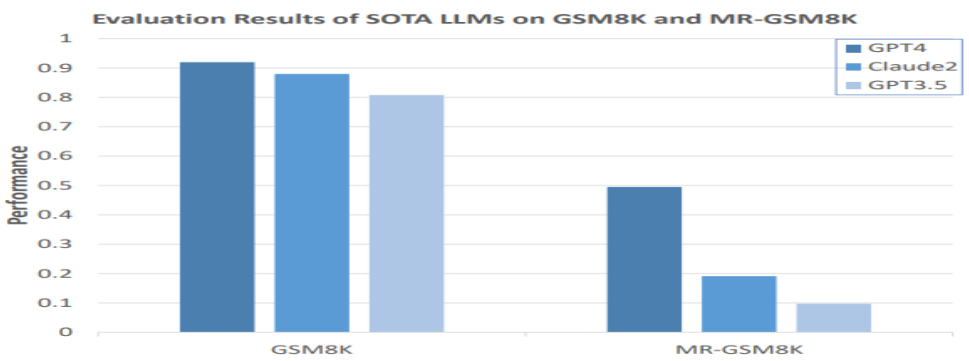
(来源:arXiv)
如上图所示,当他们把元推理范式应用到一个流行的数学评测集 GSM8k 上时,GPT4 的表现骤降一半以上,而 GPT3.5 的准确率则由 80% 以上骤降到个位数。
这说明在同一个数据集上经过简单的元推理范式转换后,模型能力会出现巨大差别。值得注意的是在范式转换之后,大模型的能力差异出现了更大的分化。
同样在 GSM8K 上取得领先效果的开源模型比如 Mammoth、WizardMath、MetaMath 等模型,它们的训练方法是这样的:针对该数据集的数据进行大量的同源增广,以让效果接近 GPT3.5。
遗憾的是,当课题组对其进行范式转换之后,开源的数学大模型效果,由原本的接近 GPT3.5、变成远逊于 GPT3.5。
这可能也表明当前流行的简单数据增强的方法,更接近于“背题”或“题海战术”,并不能真正地提升大模型的实际能力。
而作为一种通用评测范式,曾忠燊等人提出的元推理范式,能被推广到更多评测场景。
此外,本次研究中的标注难度远远超出预期。研究期间,他们针对小初级别的数学数据集 GSM8K,进行了元推理范式的改造。
这一改造方式要求标注人员针对数据集进行类似的元推理,并将元推理结果记录成评测集。
虽然仅仅是小初级别的题目,但他们发现从读题、读标准答案、再到读采样出的待评测答案,必须针对每一步进行细致的分析和推理。
而由于耗时较久,单位标注价格也就更高;同时因为难度高,对于标注人员的资质要求也高。
曾忠燊说:“我在看到报价的时候,突然想起 OpenAI 有一个论文是对数学奥林匹克竞赛的题目和解题过程进行标注,以进行强化学习的训练。OpenAI 标注的性质和内容,和我们存在部分相似的地方。”
在 OpenAI 那份名为 PRM800K 的数据集里,包含了 80 万道标注题目。保守估计一道题的标注成本是 10 美元,那么 OpenAI 数据集的价格是 800 万美元。而 OpenAI 那篇论文并没有催生特别直接的落地成果,也没有带来实用效果上的巨大提升。
“在真正了解标注的昂贵和难处后,不禁感慨 OpenAI 的财大气粗和对失败的容忍。”曾忠燊说。
另据悉,OpenAI 的创始人之一伊利亚·苏茨凯弗(Ilya Sutskever)在一次采访时被问到:“如果通用人工智能实现后他会选择做什么?”伊利亚回答说:“或许我会主动融入 AI(be part of AI)。”
阅读到上述采访报道时,当时曾忠燊并未明白什么叫融入 AI。可随着本次工作的不断推进,他隐约觉得 AI 要在认知上和人类贴合,可能很大程度上要依赖于人类不断提供丰富的反馈信号。
“这或许也是一种融入 AI 的方式吧?一种类似于干将莫邪以身殉剑的神话浪漫感。”曾忠燊说。
而在未来,他和所在团队致力于打造一个更全面、更多元的评测体系。目前,他们已经联系多家国内头部的标注公司,目标场景包括学科类、逻辑类、具身类和应用类等四个方向的元推理场景构筑。
参考资料:1.https://arxiv.org/abs/2312.17080*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


